Inleiding
Deep learning is een snelgroeiend domein binnen artificiële intelligentie. Het is een methode waarbij neurale netwerken met meerdere "hidden layers" worden ingezet om eigenschappen te leren uit data. Typische toepassingen van deep learning zijn chatbots, virtuele assistenten, gezichtsherkenning, etc.
Het domein van deep learning is het laatste decennia enorm gegroeid door:
- Een explosieve toename aan beschikbare data.
- Technologische vooruitgang in rekenkracht.
- Wetenschappelijke vooruitgang op gebied van AI methodes.
Een onderwerp dat de afgelopen jaren sterk aan populariteit heeft gewonnen is het genereren van "content" met deep learning. Denk maar aan het genereren van tekst (bvb. chatbots). In het verlengde daarvan zijn er de afgelopen jaren toepassingen ontwikkeld om content te manipuleren met deep learning. Typisch voorbeelden hiervan zijn applicaties om foto’s te manipuleren (bvb. inkleuren van zwart-wit foto’s op basis van AI).
Zulke “content generation” of “content manipulation” kan op diverse soorten content toegepast worden. Eerst en vooral zijn er tal van deep learning toepassingen voor tekst. "Natural language processing" (NLP) is een breed domein waarbij de interactie tussen computer en taal wordt ontleed. Deep learning toepassingen binnen NLP zijn legio. De meest bekende is wellicht GPT, een model - ontwikkeld door openAI - dat tekst kan schrijven. GPT-3 kan niet enkel tekst verzinnen, het is ook in staat om tekst samen te vatten, te structureren en te vertalen.
Naast tekst zijn er ook talloze grafische toepassingen van deep learning. “Computer vision” is het domein waarbij men tracht systemen te bouwen die zinvolle informatie kunnen afleiden uit digitale beelden, video's en andere visuele inputs. Deep learning in computer vision is een enorm populair domein en kent vele toepassingen: gezichtsherkenning, objectdetectie, beeldcreatie, beeldclassificatie, …).
Recentelijk bracht openAI de werelden van NLP en computer vision samen in één toepassing: Dall-E. Dit model kan beeldmateriaal genereren op basis van een beschrijving. Daarnaast kan dit model manipulaties of variaties van een bestaande afbeelding maken op basis van een caption (bvb elementen toevoegen of verwijderen).

Computer vision en NLP toepassingen hebben het laatste decennia het meeste buzz gekregen. Deep learning kan echter ook op muziek toegepast worden. We kunnen dezelfde technieken hanteren om muziek te genereren of the manipuleren. Deze gids zal een introductie geven in de wereld van muziek en deep learning. Maar alvorens we aan de slag gaan, moeten we eerst een onderscheid maken in hoe we muziek voorstellen.
Muziek kan namelijk op verschillende manieren weergegeven worden. Ten eerste kunnen we muziek afbeelden als tekst: denk maar aan akkoordenschema’s of lyrics. Daarnaast kunnen we muziek ook symbolisch afbeelden als partituur of MIDI data. Ten slotte hebben we muziek in de vorm van audio. Dit onderscheid is belangrijk, want dit bepaalt op welke manier we deep learning kunnen toepassen.
Muziek als tekst
Een van de meest rudimentaire vormen van muzieknotatie zijn akkoordenschema’s. Er bestaan vandaag reeds tal van tools om akkoordenschema’s te genereren, gebaseerd op muziektheorie. Maar ook deep learning kan hiervoor gebruikt worden. Zo kan het reeds vernoemde GPT-3 model een akkoordenschema vervolledigen op basis van een aanzet.
Ook muziekteksten kunnen met deze methode geschreven of vervolledigd worden. Opnieuw met behulp van deep learning kan men een liedjestekst schrijven gebaseerd op de discografie van een bepaalde artiest.
Muziek als partituur/MIDI
Naast akkoordenschema’s bestaan er ook uitgebreidere vormen van muzieknotatie. Hierbij wordt getracht om muziek symbolisch voor te stellen in schrift (of in data), zodat zij later muzikaal uitgevoerd kunnen worden.
Voorbeelden hiervan zijn bladmuziek, tablatuur of MIDI. Bladmuziek en tablatuur zijn verschillende muzieknotaties bedoeld om gelezen te worden door muzikanten. MIDI, daarentegen, is een symbolische representatie van muziek in discrete datapunten, bedoeld om apparaten als synthesizers, computers en samplers met elkaar te laten communiceren.
MIDI is een gangbaar, digitaal protocol om muzikale data uit te wisselen en op te slaan. Zo worden voor elke noot o.a. de volgende zaken geregistreerd:
- Toonhoogte (pitch)
- Volume
- Lengte
MIDI-data leent zich om die reden goed voor AI-toepassingen. Het zet muziek om in een behapbare sequentie van data. MIDI-data is daarenboven erg toegankelijk. Verschillende databases zijn vrij beschikbaar via het internet, bijvoorbeeld:
Toepassingen
De meest typische toepassing van deep learning in dit domein is het genereren van nieuwe MIDI-sequenties. Deze kunnen vervolgens door een synthesizer of virtueel instrument worden uitgevoerd, of worden vertaald in bladmuziek voor een muzikant. Het eindresultaat blijft dus een symbolische representatie van muziek. Enkele bestaande voorbeelden:
- Google Magenta biedt een reeks van RNN modellen aan waarmee MIDI-sequenties gegenereerd kunnen worden:
- Drums RNN: genereren van drumsequenties
- Melody RNN: genereren van monophone melodieën
- Polyphony RNN en Performance RNN: genereren van polyphone harmonieën
- OpenAI MuseNetis een neuraal netwerk ontwikkeld door openAI. Het kan muzikale composities van 4 minuten met 10 verschillende instrumenten genereren.
- FlowComposer is een virtuele assistent die helpt om nieuwe muziekstukken te schrijven.
Dezelfde groep methodes kunnen ook gebruikt worden om bestaande MIDI sequenties te manipuleren/transformeren:
- Google Magenta Music VAE is een model dat de gebruiker in staat stelt om verschillende muziekpartituren (obv MIDI data) met elkaar te mengen tot één nieuw muziekstuk.
- Google Magenta GrooVAEis een model dat groove/karakter toevoegt aan een bestaande drumpartij.
Muziek als (ruwe) audiodata
Inleiding
Het grootste onderscheid binnen de representatie van muziek is wellicht of de voorstelling symbolisch of sub-symbolisch is. De eerste kan worden voorgesteld aan de hand van discrete variabelen, de andere aan de hand van continue (geluidsgolven). Muziek als tekst of muziek als partituur zijn voorbeelden van een symbolische representatie. Muziek als audio is een sub-symbolische representatie.
Het belangrijkste verschil tussen symbolische en sub-symbolische representaties (audio) van muziek is dat deze laatste veel rijker is aan informatie. Het bevat ook informatie omtrent het geluid en het timbre van de muziek. Hierdoor is een audiobestand vele malen groter dan een MIDI-bestand, of zelfs een afbeelding. Dit brengt de moeilijkheid met zich mee dat audio eerst adequaat moet verwerkt worden vooraleer deep learning modellen er mee aan de slag kunnen.
Daarnaast is het niet voor de hand liggend om audio representaties te vergelijken. Twee waveforms kunnen er visueel zeer verschillend uitzien en toch relatief gelijkaardig klinken. Anderzijds is het menselijk oog zeer goed in het detecteren van onnatuurlijke artefacten. Wat eruit ziet als een detail in de representatie kan de klank serieus verstoren.
Mogelijke data-representaties/data-reductie methoden
MEL spectrogram
Wat is een spectrogram?
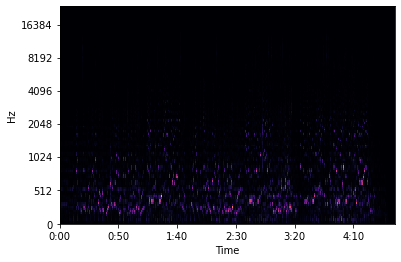
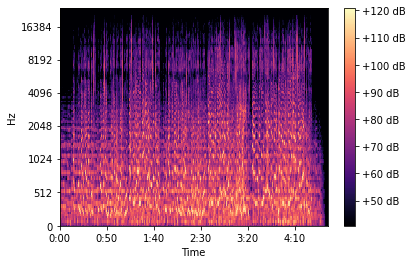
Een (geluid)spectrogram is een grafische voorstelling van een geluid in de vorm van een tweedimensionale figuur in een assenstelsel: de X-as geeft het tijdsverloop weer, de Y-as de frequentie, en de kleur of helderheid de amplitude van de betreffende frequentiecomponent op dat tijdstip. Een spectrogram toont dus hoe de frequentie of de amplitude van een geluid verandert tijdens het verloop van dat geluid.
Een audiosignaal bestaat uit verschillende geluidsgolven. Met behulp van een Fourier-transformatie kan een signaal omgezet worden in de individuele frequenties en de amplitudes van deze frequenties. Het signaal wordt omgezet van het tijdsdomein naar het frequentiedomein.
Om op te vangen dat bij muziek de signalen niet periodiek zijn, berekenen we meerdere Fourier transformaties over meerdere overlappende, afgebakende delen van het signaal. Op deze manier krijgen we een spectrogram, hetgeen een visuele representatie geeft van de loudness of amplitude van een signaal, terwijl het varieert over tijd met verschillende frequenties. Voor een betere representatie wordt de Y-as nog omgezet naar een log-schaal en de kleurdimensie naar decibels.
Wat is de MEL schaal?
De MEL-schaal (kort voor melodie) is een perceptuele schaal van toonhoogtes die door luisteraars worden beoordeeld als gelijk in afstand van elkaar. Het referentiepunt tussen deze schaal en de normale frequentie meting wordt bepaald door een perceptuele toonhoogte van 1000 mels toe te kennen aan een toon van 1000 Hz, 40 dB boven de gehoordrempel van de luisteraar.
Inverse bewerking: spectrogram naar audio
Het is mogelijk om een muziekfragment (of audiofragment in het algemeen) om te zetten naar een afbeelding door middel van een MEL-spectrogram. In Python zijn er verschillende bibliotheken waarmee dit gedaan kan worden, bijvoorbeeld de Librosa-bibliotheek.
Uitdagender is de omgekeerde operatie. De omzetting is immers enkel nuttig wanneer we de bewerkte afbeelding ook terug kunnen omzetten naar audio. Er bestaat momenteel geen exacte formule om een (MEL-)spectrogram terug om te zetten naar het originele audiosignaal, met name het schatten van de spectrale fase.
Vaak worden benaderende methodes gebruikt om de spectrale fase te schatten, zoals Griffin-Lim. In de praktijk resulteert dit echter vaak in grote verstoringen van het audio-signaal, met sterk vervormde resultaten tot gevolg. Zelfs als we dit toepassen op het originele spectrogram, zonder verdere bewerkingen, is soms het originele fragment nauwelijks te herkennen.
Een mogelijke verbetering bestaat erin om gebruik te maken van de spectrale fase van het originele audiofragment, hetgeen zou resulteren in een betere kwaliteit. Deze aanpak werd onder andere toegepast door Vande Veire et al. (2019).
Een andere oplossing is om ook in deze stap beroep te doen op een AI model, meer bepaald een Generative Adversarial Network (GAN). In een GAN werken twee modellen samen (of tegen elkaar). Het eerste model wordt getraind om nieuwe, niet-bestaande voorbeelden te genereren. Het tweede model heeft als doel om aangereikte voorbeelden te classificeren als “echt” (in onze toepassing bestaande audiofragmenten) of “vals” (audiofragmenten gegenereerd door het eerste model). De modellen worden samen getraind tot het tweede model in de helft van gevallen misleid kan worden, hetgeen betekent dat het eerste model erin geslaagd is om aannemelijke fragmenten te genereren.
De toepassing voor het omzetten van MEL-spectrogrammen naar audiofragmenten door middel van een GAN, heeft de voor de hand liggende naam MELGan meegekregen. Volgens onderzoek scoort de inversie bij een luistertest (op een schaal van 0-5) 3.61 ten opzichte van het Griffin-Lim algoritme dat een score van slechts 1.57 heeft. Zie hier voor een implementatie ervan.
Variational auto-encoders / VQ-VAE
De tweede techniek die toegepast wordt op audio is die van de VQ-VAE, een voorbeeld van een variational auto-encoder. In de volgende secties beschrijven we de techniek hiervan.
Dimensiereductie
Het doel van de (variational) autoencoder is om de input data terug te brengen naar een eenvoudige codering. Deze eenvoudigere representatie van de data kan dan gebruikt worden om andere bewerkingen mee te doen (die niet haalbaar zijn in de originele complexe representatie).
Dimensiereductie kan bekomen worden door de meest representatieve features van de input data uit te kiezen en de rest weg te laten. Een andere aanpak is om de data te mappen naar een lagere dimensie waarbij getracht wordt om zoveel mogelijk informatie te behouden. Een klassiek voorbeeld hiervan is Principal Component Analysis (PCA).
(Variational) autoencoders zijn een techniek om aan dimensiereductie te doen met behulp van neurale netwerken.
Autoencoder
Een standaard setup van een autoencoder bestaat uit twee delen: een encoder en een decoder. Eenvoudig gezegd is het doel van de encoder om de input data te reduceren naar een eenvoudigere voorstelling. Anderzijds probeert de decoder de eenvoudigere voorstelling terug om te zetten naar de originele input data. Als doel van het hele proces wordt er gezocht naar een data reductie die zoveel mogelijk informatie bewaart zodanig dat in de tweede helft het resultaat zo dicht mogelijk bij het origineel teruggebracht kan worden.
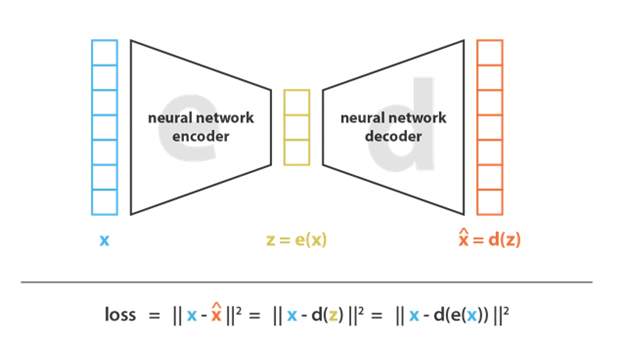
Variational autoencoder
Zonder enige regulering zouden we bij een naïeve aanpak van autoencoders ofwel eindigen met een "eenvoudigere" representatie die exact gelijk is aan de originele representatie. Hetgeen zou betekenen dat er weliswaar geen verlies is bij de reconstructie van de data, maar anderzijds ook geen dimensie reductie oplevert. Aan de andere kant van het spectrum ligt een oplossing waarbij we het model zo complex maken dat we de datapunten reduceren naar één dimensie en ieder punt een waarde geven tussen één en N. Deze punten kunnen we dan vervolgens terug omzetten naar de originele representatie. Ook hier is er geen reconstructieverlies, maar zijn de resultaten niet generaliseerbaar. Vaak is immers het doel niet alleen de dimensie te reduceren, maar ook om de informatie van de data structuur te behouden zodat ook nieuwe punten in de gereduceerde teruggebracht kunnen worden naar de oorspronkelijke dimensies.
Om een goede afweging hiervan te krijgen, willen we de doelfunctie regulariseren. Hierbij zijn twee eigenschappen van belang. Continuïteit en volledigheid. Continuïteit wilt zeggen dat twee punten in de geëncodeerde ruimte niet twee zeer verschillende punten mogen opleveren eenmaal gedecodeerd. Volledigheid duidt erop dat ieder punt uit de geëncodeerde ruimte opnieuw een zinvol datapunt dient op te leveren na decodering.
Om aan bovenstaande voorwaarden te voldoen, definiëren we variational autoencoders. Deze kan gedefinieerd worden als een autoencoder waarvan de training is geregulariseerd om overfitting te voorkomen en garandeert dat de latente ruimte goede eigenschappen (continuïteit en volledigheid) heeft om toelaat om nieuwe datapunten te genereren.
Regularisatie kan toegevoegd worden aan het encoding-decoding proces door in de encodering stap de input niet als op zichzelf staand punten te encoderen, maar als een kansverdeling over de latente ruimte. In de praktijk wordt er gestreefd naar een normale verdeling hiervoor.
Dit alles betekent dat de doelfunctie die geminimaliseerd wordt bestaat uit een reconstructieterm (hoe ver zitten we van de originele input af na decodering) en een regularisatie term (hoe ver is de kansverdeling van de latente ruimte verwijderd van een standaardnormaal verdeling). Deze regularisatieterm wordt uitgedrukt als een Kullback-Leibler divergentie.
Dankzij de regularisatieterm wordt er verhinderd dat de data in de latente ruimte te ver uit elkaar wordt geëncodeerd en worden de verdelingen aangemoedigd om te overlappen waardoor aan de vereisten van continuïteit en volledigheid voldaan worden. Hierdoor bekomen we een compactere data-representatie van het oorspronkelijke audiofragment wat vervolgens gebruikt kan worden als variabele in AI-modellen.
DDSP
Wat is DSP?
Digital Signal Processing (DSP) is het process waarbij een gedigitaliseerd signaal zoals audio, video, druk of temperatuur de input vormt om wiskundige operaties uit te voeren op het signaal. Het is technologie die terug te vinden is in hoofdtelefoons, smartphones, audio-apparatuur en entertainment systemen. In onze context is het vooral belangrijk om te weten dat het gespecialiseerd is in het omzetten van een echt, real-time audiosignaal in data waarop computationele bewerkingen gedaan kunnen worden.
Waar staat de extra D voor?
De eerste D in DDSP staat voor differentieerbaar, hetgeen wilt zeggen dat we verschillende eenvoudige DSP elementen hebben die samen het complexe, “echte” signaal vormen, controleren met behulp van heel wat parameters. Omdat het praktisch niet haalbaar is om alle parameters manueel in te stellen, wordt hierbij beroep gedaan op een neuraal netwerk.
Dankzij dit neuraal netwerk is het mogelijk om bewerkingen op het audio-signaal uit te voeren. Dit kan gedaan worden door het model te trainen in verschillende omstandigheden en op basis hiervan de parameters van het model in te stellen.
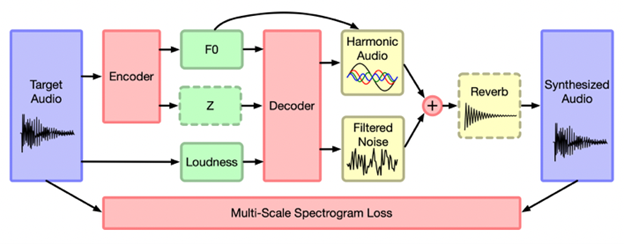
De meest toegankelijke en uitgewerkte toepassing hiervan is Google Magenta.
Toepassingen
Style transfer
Inleiding
Style transfer is een computer vision techniek waarbij men uitgaat van twee afbeeldingen, een eerste afbeelding die de inhoud bevat en een tweede die de stijl presenteert. Een typisch voorbeeld is het omzetten van een gewone foto van een persoon, dier of voorwerp naar de stijl van een bekende schilder of schilderij.
Hieronder zien we de inhoudsfoto links (foto van een hond) en de stijlfoto rechts (Sterrennacht van Vincent van Gogh). Het resultaat, de stijl van de Sterrennacht toegepast op de foto van de hond, wordt getoond in de middelste afbeelding.



Een andere toepassing is het transfereren van het uiterlijk van één voorwerp/dier/persoon naar een ander. Het standaardvoorbeeld hierbij is het omzetten van zebra’s naar paarden of omgekeerd. Dezelfde technieken kunnen toegepast worden om landschappen om te zetten van dag naar nacht, of van zomer naar winter.

Deze methodes zijn reeds goed uitgewerkt voor het domein van beeldverwerking. Toepassingen voor audio zijn echter veel minder frequent. Een mogelijke aanpak zou eruit kunnen bestaan om de audiofragmenten om te zetten naar een afbeelding, cfr. MEL-spectrogrammen, en hier de methodes uit de beeldverwerking op toe te passen.
Een interessant voorbeeld waarbij men dit heeft toegepast op MEL-spectrogrammen is met behulp van een CycleGAN.
CycleGAN
Een eerste methode om style transfer toe te passen is de CycleGAN. Zoals de naam doet vermoeden gaat het hier om een vorm van het eerder vernoemde GAN type. Het speciale aan de CycleGAN is dat het gebruik maakt van twee generatieve modellen en twee discriminatoire modellen. Het eerste generatieve model genereert afbeeldingen uit het eerste domein (bv. paarden), waarvoor het eerste onderscheidende model dan moet bepalen of het echte of valse afbeeldingen zijn. De tweede combinatie van generatief en onderscheidende modellen wordt toegepast op het tweede domein (bv. zebra’s).
Het onderscheidende van een CycleGAN is dat er een extra voorwaarde wordt gesteld van “cycle consistency”. Dit wilt zeggen dat de output van de generator als input zou moeten kunnen dienen voor de tweede generator en vice versa.
Een voorbeeld van een toepassing hiervan is hier terug te vinden. Hier werd de techniek van CycleGAN toegepast op de MEL-spectrogrammen voor twee genres van drum and bass muziek: liquid en dancefloor. Er zijn verschillende voorbeelden terug te vinden van style transfers tussen de twee genres en zelfs enkele toepassingen op voorbeelden die buiten de genres vallen. Het resultaat is een soort “remix” van een song van het ene genre in het andere.
Luister hieronder naar een voorbeeld:
Origineel (“liquid”): <audio>
Style transfer (“dancefloor”): <audio>
Timbre Transfer
Met behulp van Google Magenta kunnen we aan timbre transfer doen. Dit wilt zeggen dat we de parameters in het model gebruiken om de klank van een instrument/stem te transformeren naar een andere klank.
Op hun website Tone Transfer kan een gebruiker zelf een aantal transformaties uitvoeren, hetzij vertrekkende vanuit een voorgedefinieerde input (fluitende vogels, een cello, of potten en pannen) of een eigen opname naar een aantal mogelijke instrumenten zoals de fluit, saxofoon, trompet of viool.
De techniek werkt momenteel enkel voor monofone geluiden, dus telkens één noot tegelijkertijd spelend.
Genereren van muziek
OpenAI Jukebox
Jukebox is een neural net dat muziek genereert in verschillende genres of stijlen van bestaande bands en muzikanten. De volledige lijst van beschikbare muzikanten vind je hier.
Jukebox maakt gebruik van een aangepaste versie van VQ-VAE om audio om te zetten naar een discrete representatie. In hun VQ-VAE gebruikt men drie compressieniveaus, nl. Compressie van het 44 kHz ruwe audiosignaal naar 8x, 32x en 128x compressie. Bij deze downsampling gaan heel wat details verloren, maar informatie over pitch, timbre en volume van de audio blijft behouden.
Er worden drie prior modellen getraind op deze drie niveaus. Het model vertrekkende van de hoogste compressie bevat de informatie over de lange-termijn structuur van de muziek, waar de andere twee modellen lokale muzikale structuren overbrengen zoals timbre. Zo kan de audiokwaliteit significant verbeterd worden. Voor het trainen van deze modellen gebruikt men een vereenvoudigde variant van Sparse Transformers.
Om het model te trainen werd een nieuwe dataset samengesteld van 1,2 miljoen songs, gekoppeld aan de overeenkomstige lyrics en metadata, waaronder artiest, album genre, jaar van release, mood en keywords.
OpenAI heeft code vrijgegeven om zelf aan de slag te gaan met Jukebox in de vorm van een Google Colab. In deze colab kun je zelf aan de slag met het model en zelf parameters ingeven zoals lyrics, stijl en artiest.
Een lijst van voorbeelden is terug te vinden hier. Hier vind je heel wat verschillende mogelijkheden van het model terug, gaande van re-rendities van een song van een bepaalde artiest in een andere stijl, nieuwe lyrics gezongen in de stijl van een zekere artiest of voortzettingen van een song, waarbij gestart wordt vanuit een bestaande song maar zelf een vervolg voor wordt gegeven door het model.
IRCAM Rave
RAVE staat voor Realtime Audio Variational autoEncoder en is gebaseerd op het concept van de variational auto-encoder (VAE). RAVE maakt gebruik van een twee-staps trainingsprocedure. De eerste stap is representation learning, waarbij met behulp van een spectraal afstand een latente ruimte wordt gecreëerd. De spectrale afstand is zo gekozen dat de latente ruimte perceptueel relevant is, wat wil zeggen dat dingen die gelijkaardig klinken ook dicht bij elkaar liggen in de nieuwe ruimte. Tegelijkertijd probeert het algoritme in te schatten wat de grootte van de latente ruimte moet zijn om een compacte representatie te verkrijgen.
Voor de tweede stap wordt de encoder bevroren en wordt er verder gefocust op de decoder stap. In deze tweede stap gebeurt er adversarial fine-tuning waardoor men probeert om de decoding stap te verbeteren zodat de geproduceerde audio beter zal klinken.
RAVE kan gebruikt worden om buiten-domein reconstructies te doen. Zo kan een instrumentaal stuk gebruikt worden als input voor een model dat getraind is op stemmen en als resultaat een gedecodeerd fragment teruggeven dat klinkt als stemmen.
Daarnaast kunnen we ook samplen uit de gecreëerde latente ruimte zodat we nieuwe fragmenten krijgen in de stijl van de fragmenten waarop het getraind is. Ten slotte kunnen we ook vertrekken van een input fragment en experimenteren met een van de dimensies van de latente ruimte. Alhoewel de dimensies van de latente ruimte geen expliciete karakteristiek van de audio moeten zijn, kan men de eerste dimensies wel vaak linken aan bestaande karakteristieken. Dit is echter iets dat ad hoc bij iedere gegenereerde ruimte zal moeten worden vastgesteld.
Instrumenten gebaseerd op AI
Deep learning technieken kunnen gebruikt worden om volledig nieuwe instrumenten te genereren. Drie voorbeelden hiervan zijn NSynth, GANSynth en DrumGAN.
NSynth
Met een klassieke synthesizer kan je verscheidene parameters van audio manipuleren - zoals envelope, pitch en volume. Met NSynth daarentegen kan je volledig nieuwe, realistische instrument geluiden genereren die met een klassieke synthesizer moeilijk of onmogelijk te maken zijn. NSynth gebruikt daarvoor neurale netwerken om individuele samples te generen.
NSynth is gebaseerd op WaveNet - een baanbrekend auto-encoder netwerk dat in staat is ruwe audio te genereren.
GANsynth
Het audio synthese proces bij NSynth is relatief tijdrovend. Daarom werd GANsynth in het leven geroepen. Dit model kan beschouwd worden als een verbeterde versie van Nsynth: sneller (door het gebruik van upsampling convolutions), maar ook soepeler en muzikaler (door het gebruik van een spherical Gaussian prior.
DrumGAN
Een derde voorbeeld is DrumGAN. DrumGAN stelt de gebruiker in staat om drumsamples te genereren. Daarenboven is het syntheseproces geparametriseerd op muzikaal zinvolle kenmerken (bv. scherpte, helderheid, "boominess", etc). Dit maakt dat de muzikant controle heeft over verschillende klankkleur kenmerken van de gegenereerde samples.
Classificatie van audio / muziek
Het classificeren van muziek in verschillende genres is een gekend probleem. Doorheen de geschiedenis van de muziek is er debat geweest over tot welk genre een bepaald muziekstuk behoort. Is een nummer eerder genre A dan B, of juist een (nieuw) subgenre? Tal van projecten hebben getracht om een spectrum van genres te maken. Een algoritmisch voorbeeld hiervan is Every Noise at Once. Op het moment van schrijven bevat dit overzicht bijna 6000 verschillende genres.
Binnen het domein van Deep Learning onderscheiden we twee manieren van het classificeren van muziek, ofwel gebaseerd op het audio-fragment zelf, ofwel gebaseerd op geselecteerde karakteristieken.
De meest gangbare manier is deze waarbij vertrokken wordt van het audio-fragment zelf. Omdat typisch een audio-fragment te veel informatie bevat om bruikbaar te zijn voor de complexere modellen, wordt ook hier typisch gebruik gemaakt van MEL-spectrogrammen om de data te vatten. Tegenwoordig is er heel wat onderzoek gebeurd waarbij men op basis van deze spectrogrammen verschillende Deep Learning modellen heeft getraind om muziek te classificeren, meestal met behulp van een neuraal netwerk zoals Resnet50 of een ander zelf samengestelde CNN (ander voorbeeld), … Standaard wordt hierbij de GTZAN dataset gebruikt ter illustratie.
Omdat het MEL-spectrogram van een audio-fragment van drie minuten vaak nog te veel informatie bevat, wordt er soms gewerkt met meerdere stukjes. Men kan vervolgens op elk stukje apart de classificatie doen en met behulp van ensemble learning bepalen welke classificatie dominant is.
Naast modellen die vertrekken van het audio-fragment zelf, wordt er soms ook gebruik gemaakt van bepaalde karakteristieken. Vermits dit over het algemeen overeenkomt met een strikte data-reductie ten opzichte van het originele audio-fragment, zal dit meestal ook een lagere accuraatheid geven. Karakteristieken die hierbij typisch gebruikt worden zijn o.a.: energie, dansbaarheid, luidheid, levendigheid, akoestiek, spraakzaamheid en anderen. In de praktijk worden deze karakteristieken opgevraagd bij Spotify.
Een voorbeeld van een tool waarmee het genre van een artist (of een album) opgevraagd kan worden is Get Genre. Het is echter niet duidelijk welk algoritme hier precies achter schuilgaat. Wel lijkt het gebaseerd te zijn op Spotify.
Audio naar MIDI
Zoals reeds eerder vermeld kan MIDI beschouwd worden als een soort van bewerkbare bladmuziek voor computers. Aan de hand van deep learning kunnen applicaties gebouwd worden die audio kan omzetten naar MIDI. Op deze manier kunnen muziekopnames automatisch omgezet worden naar bladmuziek/MIDI, dewelke op haar beurt bewerkt kan worden. Er bestaan reeds tal van applicaties/modellen die deze oplossing aanbieden. Een ervan is Basic Pitch van Spotify.
Spotify Basic Pitch
Basic Pitch biedt een oplossing aan voor artiesten om hun opgenomen ideeën om te zetten naar MIDI. Het kan een complexe, polyphone opname - met verschillende instrumenten tegelijk - omzetten naar MIDI. Daarenboven is het model snel en rekenkundig licht en kan het in real-time audio naar MIDI data vertalen.
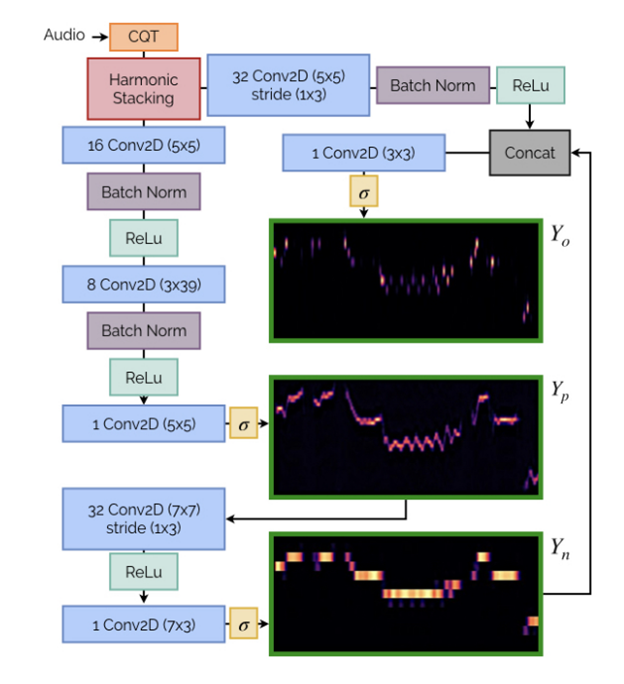
Basic Pitch is open source. Iedereen kan ervan gebruik maken via de website https://basicpitch.io.